- Übersicht
- Beschreibung
- CiMA
- Webseite
- Tilgungen SKOS
- Artikel

Forschung an historischen Manuskripten wird zunehmend von technischen Disziplinen unterstützt: Multi- und Hyperspektralbildgebung unterstützt die Wiederherstellung von degradierten oder absichtlich entfernten Inhalten; spektroskopische Analysemethoden werden zur Identifizierung und Charakterisierung von Tinten, Pigmenten und Substraten eingesetzt, was wiederum Hinweise für die Rekonstruktion des Ursprungs und der Geschichte eines Manuskripts liefert.
Jede Untersuchungsrichtung erzeugt spezifische digitale Artefakte wie Bildmaterial, spektroskopische Messungen oder menschliche Analyseergebnisse. Wenn die verschiedenen Untersuchungen von unterschiedlichen Institutionen und zu verschiedenen Zeiten durchgeführt werden, existieren die erzeugten Artefakte meist unabhängig voneinander und ohne gemeinsamen Bezugsrahmen. Dadurch ist das Potenzial zur Wiederverwendung in interdisziplinärer Forschung begrenzt und ihr effektiver Lebenszyklus endet oft mit den Forschungsprojekten, in denen sie erworben wurden.
Multi-Modal Manuscript Representations (M3R) ist ein Repositorium für die Archivierung und Dissemination von Manuskriptforschungsdaten, in dem die verschiedenen digitalen Artefakte räumlich und logisch miteinander verknüpft sind. Im Hinblick auf die Langzeitarchivierung und linked open data (LOD) wird besonderer Wert auf die Verwendung etablierter und offener Standards für Daten und Metadaten gelegt. Die resultierenden virtuellen Objekte werden über technische Schnittstellen, aber auch über einen interaktiven Web-Viewer verbreitet. Somit werden die im Repositorium verfügbaren Daten langfristig nicht nur für Naturwissenschaften und technische Disziplinen, sondern auch für Forschung und Bildung in den Geisteswissenschaften zugänglich gemacht.
'Everything is connected'
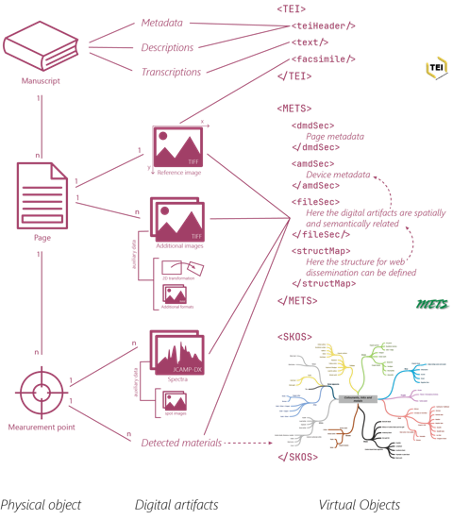
Abbildung 2 versucht, die konzeptionellen Ideen hinter M3R zu visualisieren. Auf der obersten Ebene beginnen wir mit dem Manuskript, einem physischen Objekt, das in einem Archiv oder einer Bibliothek aufbewahrt und inventarisiert wird - es kann in Form eines Kodex (eines „Buches“), einer Sammlung von Fragmenten oder sogar einer Rolle vorliegen. Informationen, die das gesamte Manuskript oder größere Teile davon betreffen – z.B. Provenienzinformationen, konservatorischer Zustand, Schriftmerkmale oder Transkriptionen – werden im etablierten TEI-Format gespeichert.
Das Manuskript wird in Seiten unterteilt, bei denen es sich um die Flächen handelt, die mit Text beschrieben sind. Bei Kodizes und Fragmenten entsprechen die Seiten meist den Blättern; bei Rollen oder anderen Objekten ist die Definition nicht so streng vorgegeben. In jedem Fall wird der Bereich einer Seite technisch durch ein Referenzbild definiert – in der Regel ein Naturfarbbild, das die jeweilige Oberfläche zeigt. Jedes zusätzliche Bildmaterial der Seite, z.B. multispektrale Bilder oder Elementverteilungskarten, ist mit einer 2D-Transformation ausgestattet, die die korrekte Ausrichtung zum Referenzbild definiert.
Innerhalb einer Seite können mehrere Messpunkte definiert werden: Sie enthalten Informationen über punktuelle Bereiche auf der Manuskriptoberfläche, wie z.B. spektroskopische Messungen, die an dieser Stelle durchgeführt wurden, oder die identifizierten Materialien. Die Positionen der Messpunkte werden in Pixelkoordinaten innerhalb des Referenzbildes der jeweiligen Seite angegeben.
Genau wie die genannten Informationen über das Manuskript im TEI-Format gespeichert werden, sollten Informationen über einzelne Seiten, Messpunkte und digitale Artefakte unter Verwendung etablierter und/oder offener Standards modelliert werden. Zum Beispiel werden Bilder als TIFF gespeichert, spektroskopische Messungen als JCAMP-DX und die an Messpunkten identifizierten Materialien (z.B. chemische Elemente, Tintensorten, Pigmente) über Konzepte einer Taxonomie im SKOS-Format angegeben.
Der „Klebstoff“ zur Verbindung aller zu einer bestimmten Seite gehörenden Informationen wird durch den METS-Standard bereitgestellt. Er ermöglicht die Modellierung der semantischen und räumlichen Beziehungen zwischen den einzelnen digitalen Artefakten sowie die Speicherung von Metadaten über die verwendeten Messgeräte.
'Easy access'
Ein Prototyp-Repository, das den oben skizzierten Konzepten folgt, ist auf der GAMS-Infrastruktur der Uni Graz implementiert, einschließlich einer intuitiven grafischen Benutzeroberfläche in Form einer Website.
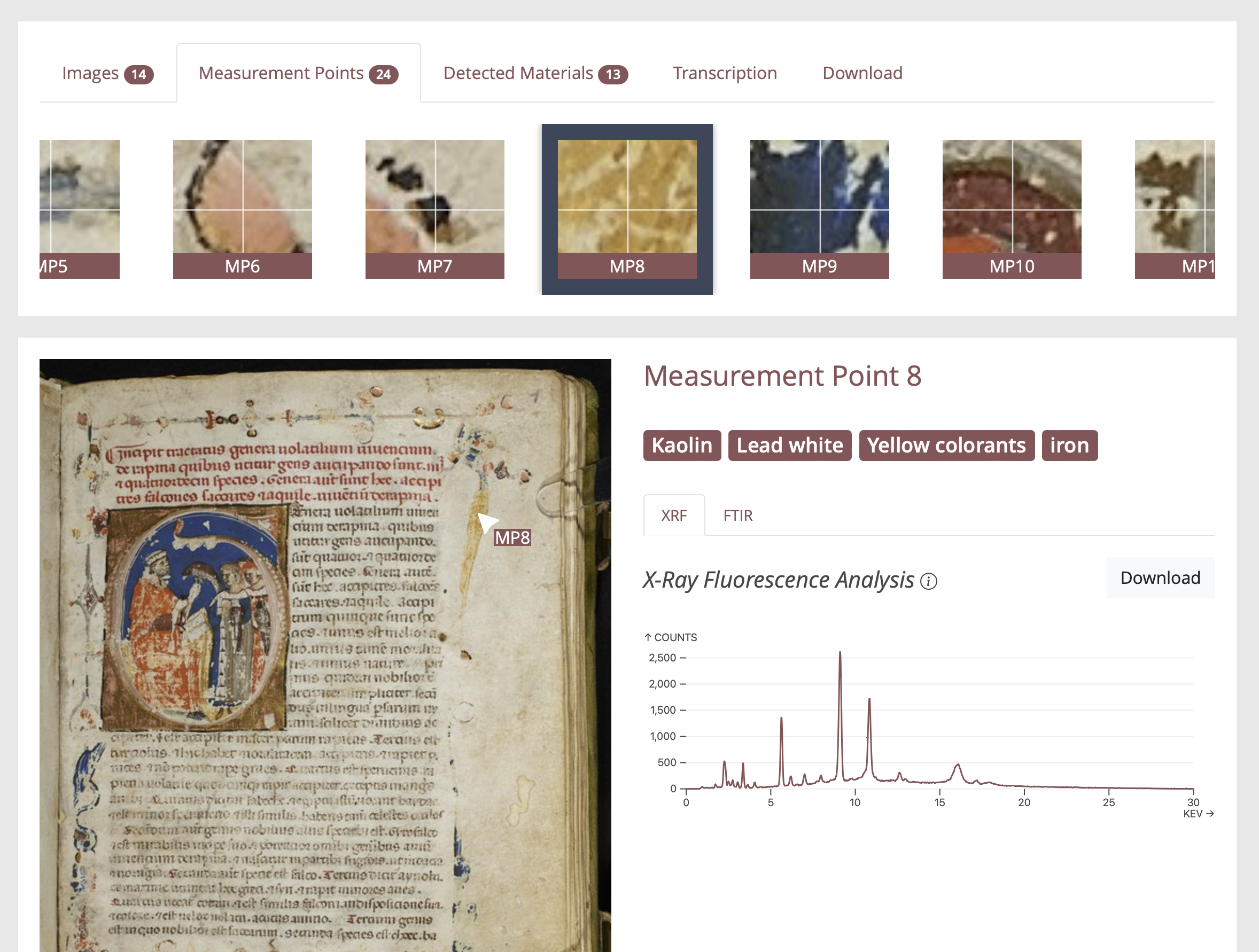
Auf der Website kann der Benutzer die Erkundung aus zwei Perspektiven starten: Aus einer objektzentrierten Perspektive ist der Benutzer an einem bestimmten Manuskript interessiert und findet die verschiedenen damit verbundenen digitalen Repräsentationen und Messungen; aus einer materialzentrierten Perspektive ist der Benutzer an dem Vorkommen bestimmter Tinten, Pigmente oder anderer Substanzen interessiert und findet die Manuskripte und Messpunkte, an denen sie nachgewiesen wurden. Abbildung 3 gibt einen ersten Eindruck der Möglichkeiten; jedoch sagt praktische Erfahrung mehr als tausend Bilder, und der interessierte Leser kann den tatsächlichen Prototyp ausprobieren.
Zusätzlich zu diesem benutzerfreundlichen Zugangsmodus werden technische Schnittstellen für automatisiertes Data Harvesting oder die Integration in Drittanwendungen bereitgestellt:
- IIIF-Bild- und Präsentations-API
- SPARQL-Endpunkt
- Direkter Zugriff auf originale Datenströme
- Umfassende Metadaten in standardisierten Formaten für alle digitalen Objekte
- OAI-PMH-Endpunkt