- Übersicht
- Bildklassifikation
- Pasetti Karte Digital
- Postkarten Kolorierung
- Annolyzer
- Redesign Datensets ÖNB Labs
- Esperanto Newspaper Excerpts
- Kontakt
Bildklassifikation in digitalen Beständen am Beispiel Bibliotheca Eugeniana Digital
Die Rekonstruktion von historischen Beständen innerhalb der Österreichischen Nationalbibliothek ist eine wichtige Forschungsaufgabe der Bibliothek selbst und ein wichtiger Service für deren Nutzer*innen. Anhand von eindeutigen Klassifikationsmerkmalen innerhalb der Bücher lässt sich die Provenienz oft zurückverfolgen.
Innerhalb des Projekts wurden Pipelines und Anwendungsfälle für das Erkennen von Provenienzmerkmalen umgesetzt. Mittels des Workflows gelingt anhand von visuellen Merkmalen (z.B. Wappen, Ex-Libris-Angaben, Supralibros) eine Zuordnung der ehemaligen Besitzer*innen. Dafür wurde mit einem convolutional neural network gearbeitet, das auf diese Erscheinungsmerkmale trainiert wurde und in dafür vordefinierten Seitenbereichen der Bücher danach sucht. Die entwickelte Pipeline wurde später im Projekt Bibliotheca Eugeniana Digital weiterentwickelt und verbessert. --> GitHub


Pasetti Karte Digital
Die unter der Bezeichnung Pasetti-Karte bekannte Donau-Karte ist eine kartografische “Bestandsaufnahme” des Donauflusses samt Uferlandschaft vor den eingreifenden Donauregulierungen der zweiten Hälfte des 19. Jahrhunderts. Die Karte zeigt den Fluss der Donau von der deutsch-österreichischen Grenze bis zum Eisernen Tor in einem Maßstab von 1:28.800 basierend auf der Franziszeischen Landesaufnahme und Stromaufnahmen aus der Zeit vor 1830.
Diese imposante Karte wurde an der Österreichischen Nationalbibliothek digitalisiert und wiederum in ihrer Gesamtheit auch online zur Verfügung gestellt. Dabei konnten die einzelnen Scans durch die automatisierte Erkennung (und manuelle Nachbearbeitung) von Bildmerkmalen auf den Bildern digital wieder so aneinandergereiht werden, dass die Karte in einem eigens dafür erstellten Viewer komplett betrachtet werden kann. --> Webapp
Postkarten Kolorierung
Das Datenset der historischen Postkarten an der Österreichischen Nationalbibliothek umfasst circa 35.000 einzelne Postkarten aus der ganzen Welt mit unterschiedlichsten Motiven und Entstehungszeitpunkten. Circa 1/5 der Karten in der Collection sind auch farbig.
Innerhalb des Projekts wurde mit Machine Learning eine Möglichkeit geschaffen, damit auch der schwarz-weiße Teil des Bestands in Farbe dargestellt werden kann. Dabei wurden ausführliche Anleitungen zur Kolorierung von Scans in schwarz-weiß erstellt, wo zwei unterschiedliche Machine Learning-Modelle verwendet werden. Einerseits wurde eine Pipeline umgesetzt, um die Daten mit einem bereits bestehenden externen Modell zu kolorieren und andererseits wurde mit transfer learning basierend auf dem farbigen Teil der Collection ein eigenes spezielles Modell angelernt und veröffentlicht. --> Webapp


Annolyzer
Mit dem Annolyzer ist es möglich eine detaillierte und tiefgehende Recherche in ausgewählten Zeitungsbeständen der Österreichischen Nationalbibliothek zu machen. Die über Annolyzer zur Verfügung gestellten Daten haben eine verbesserte OCR, die Strukturinformationen bis auf Artikelebene abbilden kann. Daher ist es möglich gezielt in Zeitungsartikeln zu suchen und eigene Forschungskorpora zusammenzustellen. Unterstützt werden Forscher*innen durch eine erweiterte Suche, annotierte Entitäten (Personen, Orte, Organisationen) und umfangreiche statistische Auswertungen und Visualisierungen. Außerdem haben Benutzer*innen die Möglichkeit die Forschungsdaten zu exportieren und mit anderen Tools weiteren A nalysen zu unterziehen. Ausgewählte Auswertungen können auch direkt in Annolyzer auf ein Datenset angewendet werden.
Annolyzer basiert auf einer Software, die ursprünglich für das NewsEye-Projekt entwickelt wurde und wurde für den Einsatz an der Österreichischen Nationalbibliothek adaptiert. --> Webapp
Redesign Datasets ÖNB Labs
Die ÖNB Labs sehen sich als zentraler Einstiegspunkt für die computerunterstützte Arbeit mit Daten der Österreichischen Nationalbibliothek. Für ihre User stellen die ÖNB Labs ausgewählte Datensets inklusive Metadaten zur Verfügung und ermöglichen so eine kreative und künstlerische Nutzung der Daten. Diese Art der Zurverfügungstellung ist essenziell für beispielsweise Fragestellungen der Digitalen Geisteswissenschaften.
Um den Anforderungen der Nutzer*innen gerecht werden zu können, ist das Angebot der Datensets einem umfangreichen Redesign unterzogen worden. In Interviews mit Usern wurden dabei die Use Cases abgesteckt und die Anforderungen gesammelt. In einem nächsten Schritt wurden in Design Sprints die Neugestaltung entwickelt, umgesetzt und dann in Tests mit Forscher*innen aus unterschiedlichen Forschungsfeldern evaluiert. Die wesentlichsten Änderungen sind eine neue übersichtliche und einheitliche Gliederung der Datensets (Info, Reuse, Preview, Data) mit Farbcodierung, einheitliche Angaben zur Rechtekennzeichnung und Nutzung der Daten und ein Daten-Sample zu jedem Datenset.
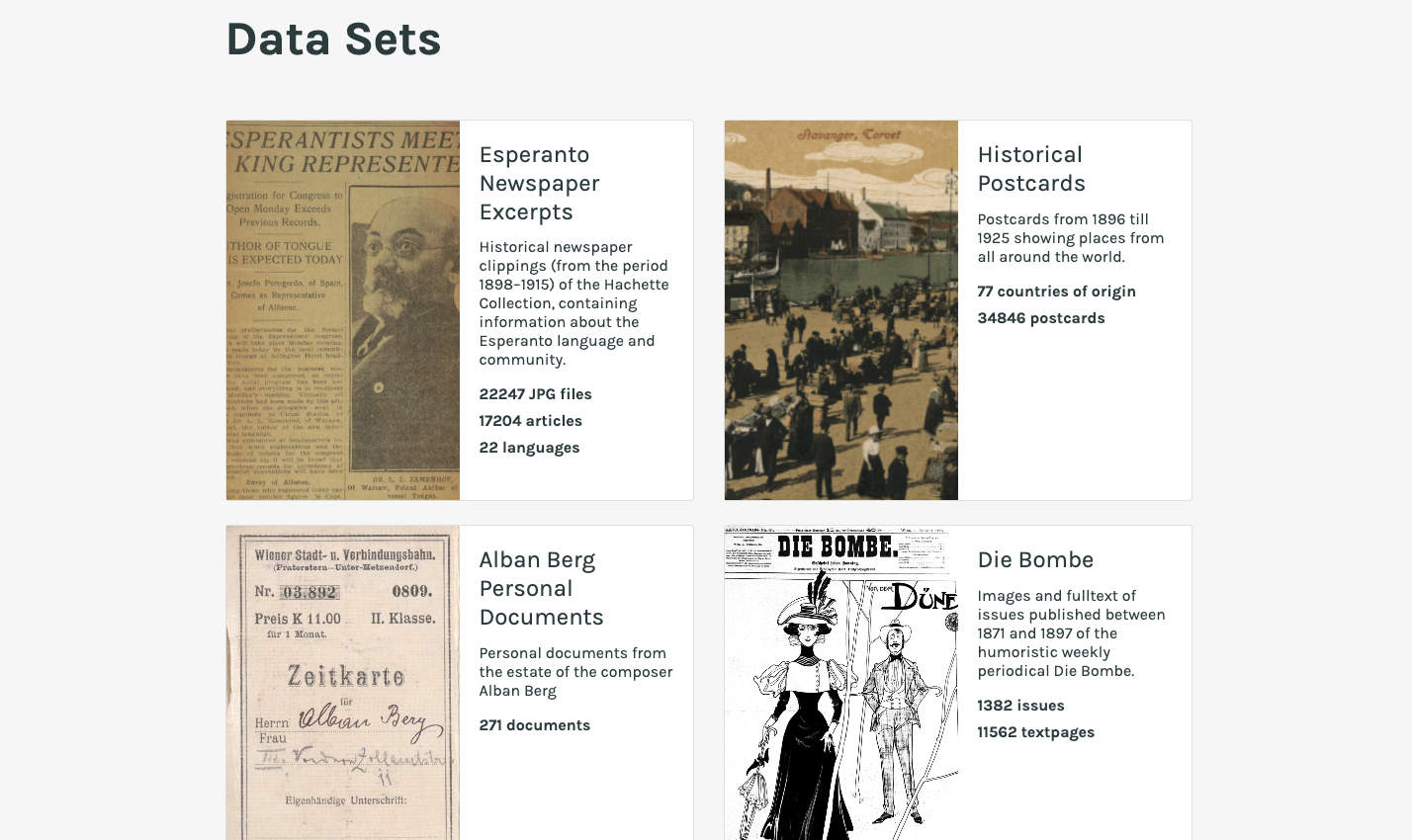

Esperanto Collection
Die Sammlung von Zeitungsausschnitten des Bestands Hachette an der Sammlung für Plansprachen der Österreichischen Nationalbibliothek, besteht aus etwa 17.000 Artikeln, die aus Zeitschriften stammen, welche in vielen verschiedenen europäischen Ländern im Zeitraum von 1898 bis 1915 veröffentlicht wurden. Die Artikel selbst berichten von Ereignissen und Personen, die mit Esperanto in Verbindung stehen, z.B. Berichte von Esperanto-Weltkongressen, und bieten daher eine hervorragende und einzigartige Gelegenheit, die Geschichte der Esperanto-Bewegung in Europa im frühen 20. Jahrhundert zu untersuchen. In diesem Projekt wurden Vorarbeiten zu einer Pipeline geleistet, die später auf den Bestand Hachette angewendet wurde. Es wurden für die sehr komplexen Aufnahmebögen der Zeitungsausschnitte neue OCR mit einem eigens dafür trainierten Modell erstellt und diese mit Metadaten, die durch Mitarbeiter*innen der Sammlung für Plansprachen zusammengestellt wurden, vereinigt. Die neu erstellte OCR-Pipeline umfasst die Segmentierung der Artikel, die Entfernung von Rändern der Scans, eine Drehung in die Waagerechte, die Texterkennung mit Tesseract und die Erstellung der Daten im ALTO-XML Format und als IIIF-Collection.